YOLOを用いたミニマップのチャンピオン検出器の作成とデータ生成手法の紹介
Contents
はじめに
YOLOという物体検出アルゴリズムを使って、こんなものを作りました。
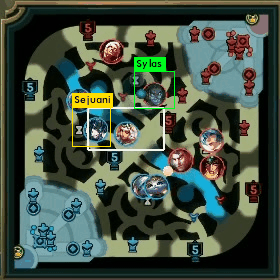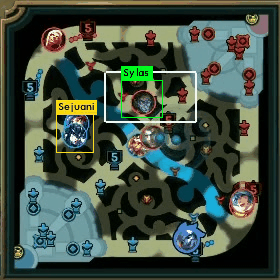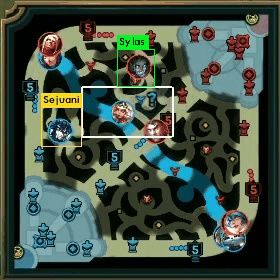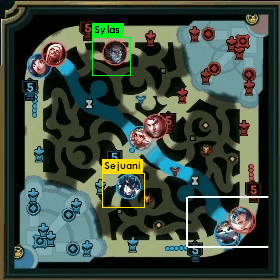
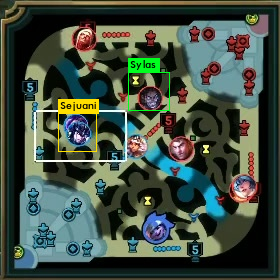
ミニマップの一部チャンピオンを検出できるようになったので、経緯とデータ生成手法について紹介しようと思います。
作成しようと思った経緯
検出器を作ろうと思ったきっかけとしては、考察に使えるデータを増やしたいというのが第一です。
これまでにRiot Games API のデータを使っていくつか考察を行ってきました。
しかし、欲しいデータがすべて詰まっているかと言われるとそうでもありません。
たとえば、1秒ごとのチャンピオンの座標、ワードが置かれた位置、サモナースペルのCD、スキルが当たったか否か、ミニオンウェーブ状況…など。
あげだすときりがないほどあります。
これらを取得しようと研究が行われていて、リプレイ動画から取得する方法[1]だったり、サーバとクライアント間で通信する情報を取得しようとする方法などが検討されています。
前者のリプレイ動画から取得するのは、光学的文字認識の技術を利用して、LoL専用の光学的文字認識を開発して、情報の取得に成功しています。
後者のネットワークから取得する方法は、後に出てくるWeb socketで取れるみたいなのですが、私は成功したことがありません。
このように、API 以外からも情報が欲しいという背景があって、何か情報をとれないだろうか?ということを調べていくうちに、以下の検出器を見つけました。
取得元: https://github.com/farzaa/DeepLeague

その名も DeepLeague です。
GitHubのリポジトリも公開されていて、ミニマップのチャンピオンを検出するというものです。
これを使うことで、取れないとされていた、1秒ごとのチャンピオンの座標を取得することが可能です。
また、紹介記事[2][3]にも書かれていますが、このデータを取得することで、プレーヤーの動きに関する多くの分析を行うことができます。
たとえば、良いプレイをしたときのプレイヤーの動きを分析し、新しい戦略を考えたり、弱点を埋めることができます。
これと同じことがしたいということで、今回の検出器を作成したことになります。
既存手法(DeepLeague)でも、取得できない情報があるため、その解決案をまとめています。
その説明の前にまずは、DeepLeague について説明したいと思います。
DeepLeagueの紹介
概要
本章では、DeepLeagueについて技術的な説明を加えながら紹介していきます。
まずは、DeepLeagueの定義から、
DeepLeagueは、Computer Vision, Deep Learning、League of Legendsを組み合わせて、
ゲームのピクセルにエンコードされたデータに開発者が簡単にアクセスできるようにすることで、
LoLの分析を次のレベルに移行するための最初のアルゴリズムとデータセット(100,000以上の画像)である。参照元: https://medium.com/@farzatv/deepleague-leveraging-computer-vision-and-deep-learning-on-the-league-of-legends-mini-map-giving-d275fd17c4e0?
と、あります。
要はミニマップの画像を与えると、チャンピオンの境界ボックスとクラス(ここでは、チャンピオン名)を返してくれます。
その情報をミニマップに描画すると、上で載せたような画像が得られるわけですね。
このようにクラスと一緒に境界ボックスの位置を予測することを物体検出と呼びます。
近年ディープラーニングを用いて、研究されている分野です。
では、そもそもどうやったらその物体が検出できるのか、ということについて、次節で述べていきます。
物体検出
物体検出は画像を取り込み、画像の中から定められた物体の位置とカテゴリ(クラス)を検出することを指します。
検出器には、ニューラルネットワークが用いられることが多く、出力結果と教師データの差分を小さくするように重みを調整する、いわゆるディープラーニングを行うことで、精度の高い検出器が作られます。
検出器が作られる最中を図にすると以下のようになります。
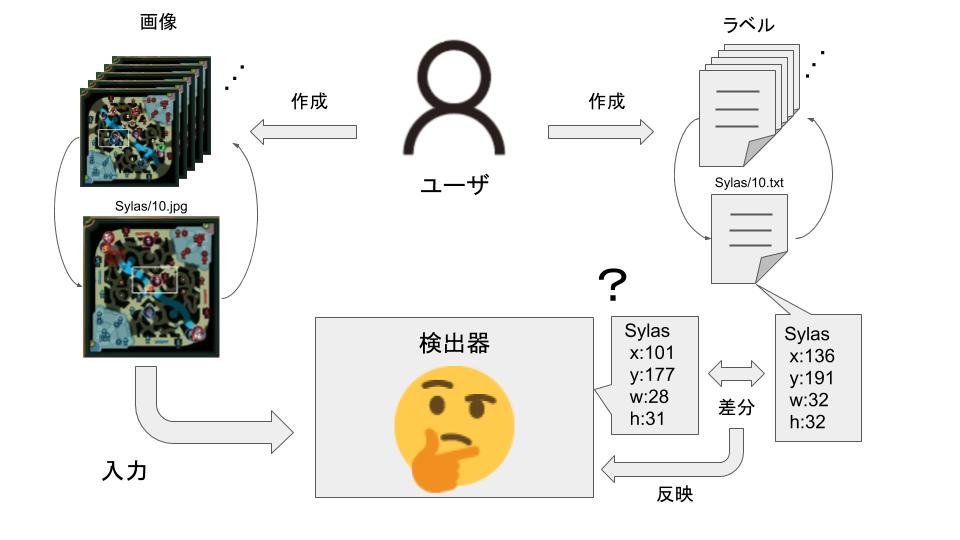
ユーザは以下の2つを用意します。
- 画像: 検出したい物体が写っている画像
- ラベル: 物体が画像のどこに写っているかの座標
検出器は入力画像から、クラスの位置予測を行います。
当然学習したては、間違った位置を予測します。
これをあらかじめ用意しておいたラベルと比較し、その差分を少しずつ修正するようにニューラルネットワークに反映し、重みを調整します。
この一連の流れを学習と呼びます。
学習を何万回と繰り返し、出力結果と教師データの差分が小さくなったとき、学習終了の目安となります。
学習を終了した検出器を使った物体検出の様子が以下のようになります。
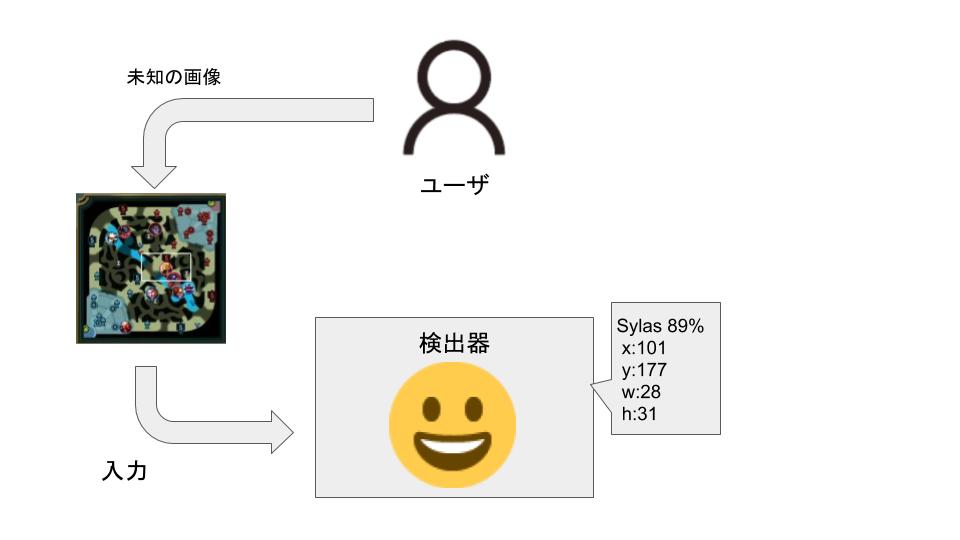
未知の画像を入力したとしても、学習の結果をもとに、クラス名と位置の予測を行ってくれます。
このようにして検出されているわけですね。
検出器に使われるアルゴリズムは、これまでに様々なものが提案されており、速さ、精度が手法によって異なってきます[4]。
DeepLeague でも、 SSD, R-CNNs, Faster R-CNN, YOLOを検討した結果、速さを重視し、YOLOを選択したと書かれています。
私が作成したものもYOLOを用いました。
画像とラベルは1クラスあたり最低100枚必要で、1000枚ぐらい用意することが推奨されているようです。
検出精度を上げるためには、さらに必要で、5000~10000枚用意するとよい、といった意見もあります。
DeepLeagueでは、画像とラベルを100,000個用意したことが推されています。
1クラスあたり、何枚用意したかは言及されていませんでしたが、推測するに2000枚弱(100,000ラベル / 55クラス)ほど用意しているように見えます。
次節でこれらの準備方法に述べていきます。
データの準備方法
前節で検出器の学習を行うためには、画像とラベルが必要だと述べました。
画像は任意のものを準備すればよいのですが、ラベルを準備するためには、アノテーションという作業を行います。
アノテーションとは、あるデータに対して関連する情報を注釈として付与すること(wikiより)を指します。
つまり、ここでは、画像に対して、ラベルを注釈として付与することという意味になります。
アノテーション作業をやりやすいように、いくつかツールが存在し、今回私が使用したBBox-Label-Toolだと、こんなかんじに作業を進めます。

これは、Sylasのラベルを生成している図です。
クリックして、ドラッグ&ドロップすると、左上、右下の座標がBounding Boxesに出力され、「Next >>」を押下すると、座標がファイルとして保存され、次の画像のアノテーション・・と繰り返します。
この作業、簡単そうに見えますが、最低でも5秒ほどかかります(画像開く、見つける、囲む、保存する)
仮に10万枚のアノテーション作業を手動で行うと、単純計算で、50万秒、約8000分、138時間、1日8時間労働として 17.25人日 必要となってきます。
もはや、1人月ぐらいの作業といえるでしょう。
これだけの人手を確保できるのであれば、手動でも問題ないかもしれませんが、大手企業でもない限り厳しいですね。
余談ですが、機械学習エンジニアの募集要項に、スタッフの手により、ラベル付け完了したデータがあります!みたいな要項を見たことがあるので、このような仕事はあるみたいですね。
DeepLeagueの作成者は、そんな人手を確保できないので、工数をかけずにデータを用意する方法が紹介されているので、それについて次節で説明します。
データ生成手法
一言で言うと、DeepLeagueは、LCSからの情報をもとに、データを生成しています。
具体的には、lolesports.comでLeague of Legendsの試合を視聴する際に、Web socketで接続すると、その中にチャンピオンの位置情報が含まれているそうです。
彼らはこれをMysterious Web Socketと呼び、LCS, LCS EUの試合を監視し、Mysterious Web Socketでやり取りされる情報をJSONに保存していました。
このJSONファイルにチャンピオンの位置情報が含まれるため、JSONが表すときのLCS, LCS EUの試合の動画があれば、学習させる画像とラベル相当の情報を作成することができます。
ただ、これもそう簡単にはいかず、正しいデータにするために、様々な工夫が行われています。
ここで詳しく説明はしませんが、具体的には、JSON と 試合のミニマップをどう一致させる?
Google Cloud Vision APIを使いたいけど、お金がかかってしまう問題にどう対処しよう・・などを冗談を交えて説明されているので、詳しく知りたい方は、参照してみてください。
また、技術的な話になりますが、学習させる際の工夫なども書かれていますので、ぜひ。
新しいデータ生成手法を考えました
既存手法の課題
前章で紹介したようにDeepLeagueはとてもよくできていて、学習済みのデータも公開されているため、誰でも使用できるようにも整備されています。
本当に素晴らしいです。
ただ、2017年のLCSで使用されたチャンピオンを使用している?ためか検出できるチャンピオンが限られています。
これを2019年版にアップロードしようと試みましたが、Mysterious Web Socketから何も得ることはできませんでした…
私の設定が間違っているのか、Mysterious Web Socketが閉じられたのか、真相はわかりませんが、JSONを取得できない状況になりました。
設定方法を確認しようにも、プロリーグが開催されている期間であれば、試せますが、開催されていない期間もあります。
また、プロリーグが始まったとしても、プロが使用するチャンピオンしか情報を取得できません。
Teemoを検出したいんだけど・・という要求に対して、プロが使うまで待つしかないね、といった回答しなければなりません。
以上のことをまとめると、最新バージョンに対応し、より良いものにしていくためには、以下の2つの課題を解決する必要があります。
- 種類の課題: LCS, LCS EU以外のチャンピオンの情報も収集できるように。
- 期間の課題: プロリーグが開催されていなくても、情報を収集できるように。
APIとリプレイからの情報収集
なんとか上記課題を解決した手法がないかと思考錯誤しました。
いろいろ試して、行きついた先が、APIの位置情報を利用しようという考え方です。
要は欲しい情報として、位置情報とそのときのミニマップが存在すればよいわけです。
なので、取得できる位置情報から、ミニマップの状況を作ればよいのではないかという考えました。
取得の流れは以下のとおり、

LoLの各試合は、Match IDが割り当てられていて、それを用いてRiot Games APIに問い合わせると、様々な情報を得ることができます。
位置情報でみると、60秒で割り切れる時刻のとき(例: 1:00, 2:00, …)、Killが発生した場所の座標が返ってきます。
Killが発生した場所 ≠ チャンピオンの場所であるため、使うのは難しいです(KarthusのRで倒した場合など)。
なので、60秒毎に記録されている各チャンピオンの位置情報のみを使用しました。
また、情報を得るだけでなく、リプレイを起動することもできます。
Match ID を用いて、リプレイ起動を行い、開始されるまで待機します。
リプレイが開始(ゲームが開始)されたら、60秒毎にミニマップを保存していきます。
ここで、注意が必要なのが、保存している場面が本当に60秒で割り切れるかどうかを確認していないことです。
保存するタイミングは開始と同時に相対的にしか計っていないため、ずれている可能性もあるんですね。
なぜ確認していないかについては、参考サイト[3]のPart3 を参照してください。
Google Vision API を使う必要が出てきて、制約事項が増えてしまうんですね。要はめんどうでした。
この部分をずれないようにするために、別の方法で労力をかけました。
具体的には、リプレイ開始確認処理の高速化です。
ずれうる可能性として、この部分が一番高くなると考えたからです。
逆に言ってしまうと、この部分さえ合ってしまえば、リプレイが停止されない限り、ずれることはない(はず)です。
リプレイが停止した場合は、そもそもその試合全体のデータが使えなくなってくるので、除外すればよいだけです。
C++で書き直すことで、私が求めるくらいの速さを手に入れ、問題なく動作しているつもりです。
以下にAatroxの情報で、実際に得られたミニマップに座標情報を描画した例です。

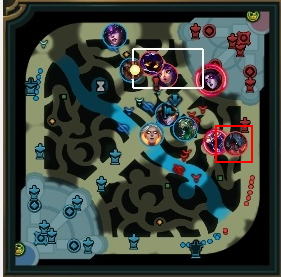
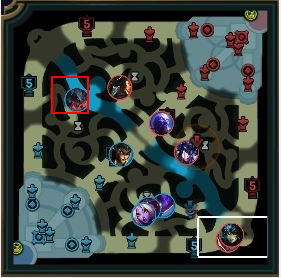
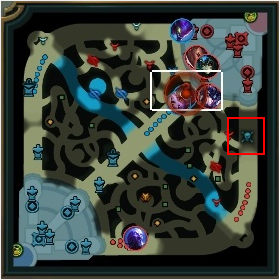
上2枚が求めている情報が取れている例になります。
全部が綺麗に取れているわけではなくて、なかには、3枚目のようにずれているものもあります。
4枚目は、そもそも取得しないべき情報ですね。
APIの仕様上、力尽きている場合は、力尽きた場所の位置情報が返ってくるため、4枚目のように期待していない情報が取れる場合もあります。これは手動で削除しました。
このように力尽きている場合を除いて、ある程度取れていることがわかります。
1ヶ月ほど動作させたところ、192319組の画像とラベルを作成することができました。
ただ、146チャンピオン(Senna実装当初)で上記数字のため、100組しかデータが存在しないチャンピオンから6000組 存在するチャンピオンとまちまちです。
今後はこのバラつきがなくなるように、Match IDを取得する必要があると考えています。
おわりに
DeepLeague の紹介をし、そのデータ生成方法の課題について述べ、課題を解決できる手法を示しました。
これらのデータに実際に一部のチャンピオンを学習させ、検出器を作ったのですが、あまり精度がよいとは言えませんね。
精度をあげるために、データの数を増やすのか、学習の回数を増やすのか、どうすべきなのかまだわかっていないため、もう少し時間がかかりそうです。
パラメータを調整しつつ、学習を繰り返す必要があるのでしょうか。
とはいえ、チャンピオン名の検出は成功しているので、次に繋がる検出器はできたと思います。
最終的にはすべてのチャンピオンを検出できるようにデータの収集、学習を行っていきたいと思っています。
不明な点・間違っている点などがありましたら、お気軽にコメント、Twitter にてお知らせください。
参考にしたサイト
- [1] MAYMINP.: An Open-Sourced Optical Tracking and AdvancedeSports Analytics Platform for League of Legends. In2018 MIT SloanSports Analytics Conference.
- [2] DeepLeague: leveraging computer vision and deep learning on the League of Legends mini map + giving away a dataset of over 100,000 labeled images to further esports analytics research